
Похожие вопросы
2025-06-01 00:05:14
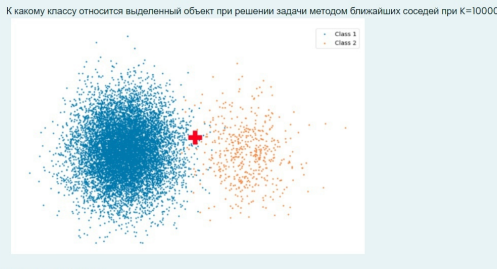
К какому классу относится выделенный объект при решении задачи методом ближайших соседей при К 10000?
Другие предметы Университет Методы классификации анализ данных метод ближайших соседей класс объекта KNN выделенный объект задача классификации университетский курс машинное обучение
2025-06-01 00:05:32
Метод ближайших соседей (k-nearest neighbors, KNN) — это алгоритм, который используется для классификации объектов на основе их сходства с другими объектами в обучающем наборе данных. Давайте разберем, как работает этот метод и что происходит, когда мы устанавливаем значение K равным 10000.
Шаги решения:
- Определение K: В методе KNN K — это количество ближайших соседей, которые мы будем учитывать для классификации нового объекта. В вашем случае K равно 10000.
- Подбор ближайших соседей: Алгоритм находит 10000 ближайших соседей к выделенному объекту из обучающего набора данных. Это значит, что он будет искать 10000 объектов, которые наиболее близки по определенному метрике (например, евклидова расстояние).
- Классификация: После того как 10000 ближайших соседей найдены, алгоритм будет определять класс выделенного объекта на основе классов этих соседей. Каждый из 10000 соседей будет голосовать за свой класс.
- Проблема с K = 10000: Если в вашем обучающем наборе данных меньше 10000 объектов, то алгоритм будет использовать все доступные объекты для голосования. Это может привести к тому, что класс будет определяться на основе всех объектов, что может снизить точность классификации. Если же объектов больше 10000, то алгоритм будет учитывать только 10000 ближайших, что может привести к тому, что результат будет сильно зависеть от конкретного выбора соседей.
- Вывод: Класс выделенного объекта будет определяться на основе голосования 10000 ближайших соседей. Если классы соседей распределены равномерно, то может возникнуть ситуация, когда класс будет неопределенным или не совсем точным.
Таким образом, использование K равного 10000 может быть неэффективным, особенно если размер вашего обучающего набора данных меньше этого значения. Рекомендуется выбирать значение K, которое меньше, чем количество доступных объектов, чтобы избежать подобных проблем.